Reddit is the [8th most visited site](http://www.alexa.com/topsites/countries/US" target="_blank) in the US and allows users to submit, comment, and vote on links. The site is divided into tens of thousands of communities, called subreddits, which are each focused on topics both broad ([/r/Fitness](http://www.reddit.com/r/Fitness" target="_blank)) and narrow ([/r/westworld](http://www.reddit.com/r/westworld" target="_blank)).
These subreddits are not organized in any systematic way though, and Reddit users usually find out about new subreddits through word of mouth.
In order to develop the most comprehensive map of these subreddits to date, I analyzed over 1.2 billion comments made by users across 47,494 subreddits (from January 2015 to October 2016) to create a mathematical representation of each subreddit. The core principle is "guilt by association" - if the same user comments in two subreddits they are likely to be linked in interest. So, each subreddit can be represented by a mathematical vector that summarizes how often users commented in that subreddit and also each of the other subreddits.[1]
Interactive Exploration Tools
Subreddit Universe Map
Below is an interactive clustering of subreddits based on user comment co-occurrence. Subreddits that are closer together on this plot are more likely to have users that comment in both. Note that you'll want at least 4GB of free memory on your machine to run it with all the subreddits:
I've also created a large zoomable image file of the clustering including all 47,494 subreddits that you can download [here](https://github.com/trevormartin/shorttails/blob/master/subredditalgebra/plots/tsneplotlarge.png). If you want to open the subreddit map in its own window click here.Subreddit Similarity Calculator
The same mathematical representation that we used to cluster subreddits can also be used to rank and quantify subreddit similarity to a query subreddit. E.g. What are most similar subreddits to [/r/science](http://www.reddit.com/r/science" target="_blank)? (It's [/r/askscience](http://www.reddit.com/r/askscience" target="_blank) followed by [/r/Futurology](http://www.reddit.com/r/Futurology" target="_blank)).
Excitingly though, this mathematical representation also allows us to combine subreddits to find subreddits that represent different combinations (e.g. [/r/nba](http://www.reddit.com/r/nba" target="_blank) + [/r/Cleveland](http://www.reddit.com/r/Cleveland" target="_blank) = [/r/clevelandcavs](http://www.reddit.com/r/clevelandcavs" target="_blank); the Cavaliers are Cleveland's NBA team).[2]
Below is an interactive tool for calculating subreddit similarity, either to a single subreddit if you enter one or to any combination of up to three subreddits:
The closer the similarity score of a subreddit is to 1, the more similar it is to your query. If you want to open the subreddit similarity calculator in its own window click here.Interesting Examples
Subreddit Universe Map
The subreddit clustering map gives rise to some broad categories of subreddits that I've highlighted in the image below:
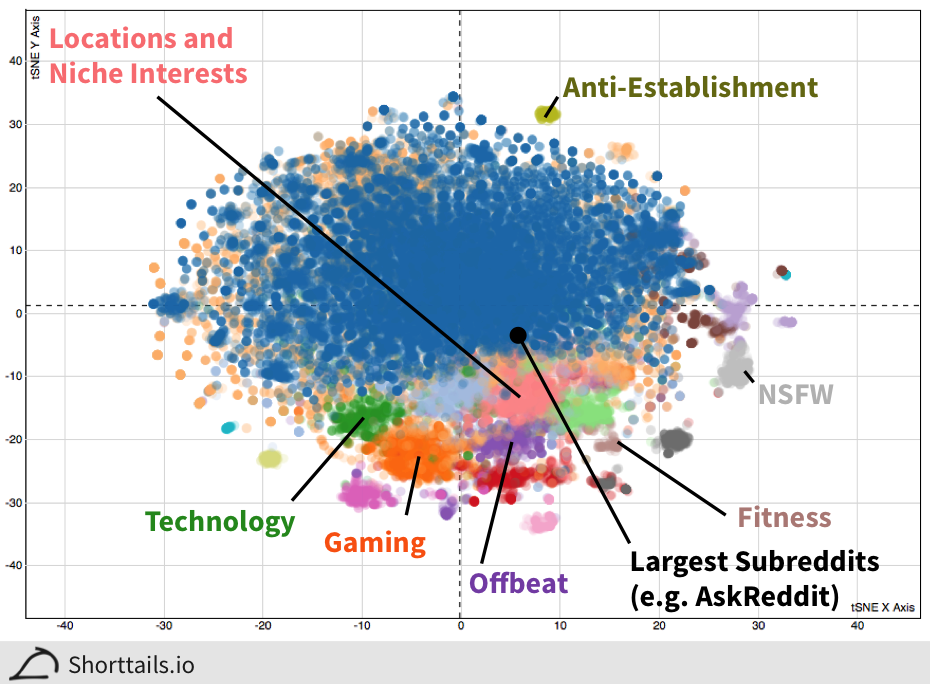
As you can see (and confirm in the interactive plot), subreddits cluster nicely into semantically related groups such as technology related subreddits (e.g. [/r/apple](http://www.reddit.com/r/apple" target="_blank) and [/r/Ubuntu](http://www.reddit.com/r/Ubuntu" target="_blank)). And when we zoom in we can see that there is also interesting and informative finer-scale resolution, such as when we look at a cluster of music subreddits in the following image:
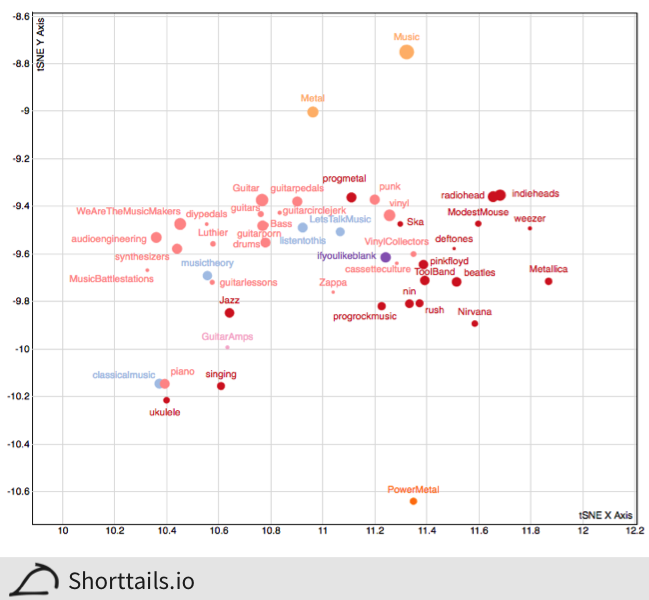
Classical music ([/r/classicalmusic](http://www.reddit.com/r/classicalmusic" target="_blank)) is separated from indie music ([/r/indieheads](http://www.reddit.com/r/indieheads" target="_blank)), with jazz in between ([/r/Jazz](http://www.reddit.com/r/Jazz" target="_blank)). Surprisingly (?) power metal ([/r/PowerMetal](http://www.reddit.com/r/PowerMetal" target="_blank)) is relatively far from metal ([/r/Metal](http://www.reddit.com/r/Metal" target="_blank)), suggesting that there may be a uniquely striking difference to this sub-genre - interestingly wikipedia notes that power metal is heavily influenced by classical music.
Subreddit Similarity
Aside from the ability noted above to locate a city's sports teams by combining the city's subreddit and the national sports league, there are many other interesting subreddit similarities we can calculate. As a simple example, the image below shows the analysis of subreddits similar to [/r/hiking](http://www.reddit.com/r/hiking" target="_blank):
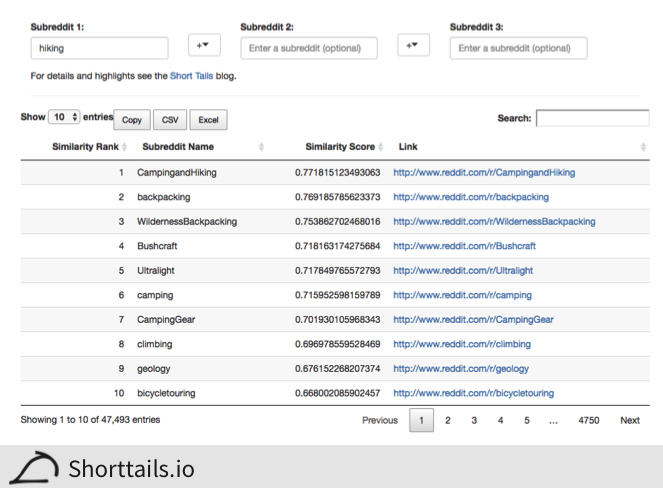
We can see that we indeed get back a list of subreddits that would definitely interest someone with a passion for hiking. Looking at subreddit combinations we see:
The combination of interest in books and scifi suggests a strong interest in written science fiction:
[
/r/books](http://www.reddit.com/r/books" target="_blank) + [/r/scifi](http://www.reddit.com/r/scifi" target="_blank) = [/r/printSF](http://www.reddit.com/r/printSF" target="_blank)
The combination of cities in the bay area results in the bay area subreddit:
[
/r/sanfrancisco](http://www.reddit.com/r/sanfrancisco" target="_blank) + [/r/sanjose](http://www.reddit.com/r/sanjose" target="_blank) + [/r/paloalto](http://www.reddit.com/r/paloalto" target="_blank) = [/r/bayarea](http://www.reddit.com/r/bayarea" target="_blank)
The sky is the limit on using this subreddit "algebra" technique to find interesting combinations - feel free to email me with interesting results you find and I will highlight them here!
Methods
Reddit comment data is from a great collection hosted on Google's BigQuery.[3] In particular, credit to Reddit users /u/stuck_in_the_matrix and /u/fhoffa for downloading and uploading the data.
All analysis code available on Github here.
Creation of subreddit vectors:
- This analysis is structured around the idea of latent semantic analysis, where instead of words and paragraphs we have subreddits and users.
- First, in order to save computational time and storage space 2,000 subreddits were selected as "representative subreddits" in BigQuery by ranking subreddits by the number of unique users and choosing subreddits 201 through 2,200 using SQL.[4]
- The BigQuery tables of 1.2 billion raw Reddit comments were processed into an output table of the number of shared users between the 2,000 "representative subreddits" and each of the other 47,494 subreddits using SQL. A user was only counted as shared if they had authored 10 or more comments in each subreddit.
- This raw matrix of subreddit user overlaps was then converted to a matrix of positive pointwise mutual information; in short each count element is converted to a joint probability and then each count's divergence from independence is quantified as the PPMI, more details here.
Creation of subreddit universe cloud
- The subreddits were "clustered" (the dimensionality of the subreddits was reduced to only two dimensions) by using the t-Distributed Stochastic Neighbor Embedding (t-SNE) algorithm on the PPMI matrix with a perplexity parameter of 50.
Subreddit Similarity Scoring
- Similarity between subreddit vectors in the PPMI matrix is quantified using the cosine distance, as this has been shown to work well for most LSA applications. In short, the cosine distance is a quantification of the angle between the PPMI subreddit vectors, as shown in the image below:
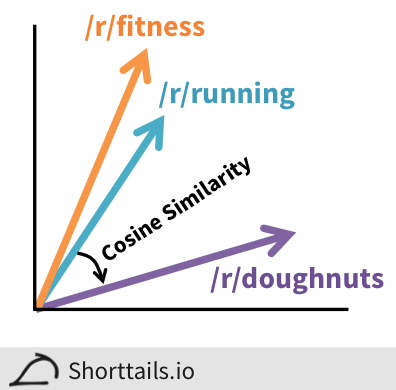
- Above, subreddits are shown as simplified two-dimensional vectors although in the real analysis they are 2,000-dimensional. Here, the subreddits [
/r/Fitness](http://www.reddit.com/r/Fitness" target="_blank) and [/r/running](http://www.reddit.com/r/running" target="_blank) are more similar to each other than to [/r/doughnuts](http://www.reddit.com/r/doughnuts" target="_blank) because the angle between them is smaller. Subreddit vectors can be added and subtracted as normal and then the angles recalculated to find the most similar subreddits to a combination.
Have more ideas or suggestions about how to use this data? Drop a line at suggest@shorttails.io and maybe it can be added to this blog!
Technically the vector only represents co-occurrence of comments with 2,000 of the top subreddits, but this performs essentially the same as co-occurrence with all 47,494 subreddits but is much easier to compute. See the Methods section. ↩︎
When this same basic technique is used with words instead of subreddits the most famous example is (king - man + woman = queen). See here for more details. ↩︎
Some may also be interested in a smaller/older but more easily accessible Reddit comments data set available here. This data set is part of this great paper. The 2015 data only is also available here. ↩︎
The first 200 subreddits are not included as previous studies have shown increased performance when excluding the most common elements (intuitively they will not have much usable information since they are so ubiquitous). ↩︎